
XPath2Doc中文绿色版(通用网站数据采集及Doc生成工具)
立即下载- 软件大小:18.1 MB
- 软件版本:最新版本
- 软件分类:网络软件
- 软件语言:简体中文
- 软件支持:Win All
- 发布时间:2020-09-29 22:34:50
- 软件评分:



- 软件介绍
- 相关下载
- 同类最新
- 软件攻略
- 评论留言
- 下载地址
XPath2Doc中文绿色版(通用网站数据采集及Doc生成工具)分属于离线浏览,officeba免费提供XPath2Doc中文绿色版(通用网站数据采集及Doc生成工具)下载,更多XPath2Doc中文绿色版(通用网站数据采集及Doc生成工具)就在officeba。
XPath3Doc是一个全自动收集网页页面转化成Word docx文档的专用工具,带天眼查、天眼网收集配备,应用XPath3Doc必须自身在WebBrowser对话框里边手工制作登陆,并寻找必须的数据信息网页页面,随后点一下程序流程按键开展收集,因此是个全自动的网页页面数据信息添充Docx专用工具。
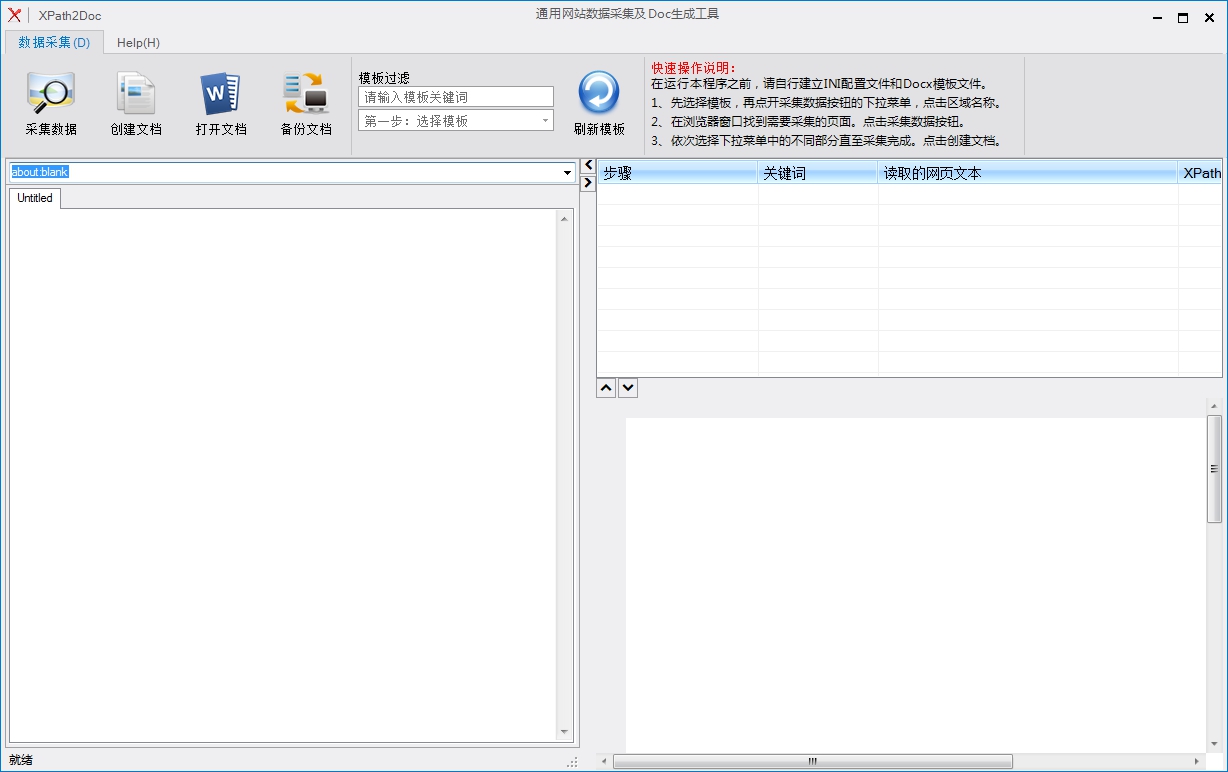
XPath2Doc中文绿色版(通用网站数据采集及Doc生成工具)原理
网页页面的每一个原素,都能够表明变成XPath句子,因此我们可以载入打开浏览器的网页页面源码,根据XPath句子获得网页元素中的文字。
XPath句子的获得方法:
一般 我们可以应用Google的Chrome浏览器开启网页页面,按F12调成微信开发工具页面,在ELements菜单栏下,伴随着电脑鼠标的挪动能够见到网页页面被黑影遮盖,点开三角符号,能够更进一步精准定位精确的部位,直至寻找最后必须的数据信息部位。在寻找的文字上点鼠标点击,在弹出来的莱单中,挑选Copy-Copy XPath,随后黏贴到文本文档就可以获得必须的XPath句子。
这儿必须表明一点:假如复制出去的XPath句子中有/tbody会危害收集,程序流程內部对于此事难题开展了解决,但很有可能会在一些特殊情况下还会危害数据收集,能够手工制作除掉。
XPath2Doc中文绿色版(通用网站数据采集及Doc生成工具)软件环境
Windows7 Sp1电脑操作系统请安裝下边的部件(关键:VC库如果不安裝,本程序流程无法启动):
VC2017往上
.net framework 4.5.2
在Windows10系统软件下所述部件一般内置,不用独立安裝。Windows10 1903运作根据。
不兼容Windows XP电脑操作系统。
XPath2Doc中文绿色版(通用网站数据采集及Doc生成工具)操作指南
1、本程序流程工作中必须三个环境变量:General.ini,自定.ini,自定模版.docx。后2个文件夹名称自身界定。
General.ini文件中界定了INI文档和Docx模版文档的储放文件目录,可以不填,默认设置是程序流程所属文件目录。
自定.ini、自定模版.docx是pc软件使用人自身建立的网页页面收集XPath句子及最终转化成文档常用的Docx模版,实际设定方式可以看ini文件中的表明。留意,Docx模版文档中的“@《#0001#》@”这类的标识符是在INI文档中界定的用以更换网页页面收集內容的标识字符串数组。ini文件中界定了更换关键词的前后缀名和模版文件夹名称。
2、应用本程序流程前,请先创建你要自身的INI环境变量和Docx模版文档。(实际能够参照附加的天眼查、天眼网2个环境变量和起诉书模板)
必须表明的是,模版文档适用对文本文档的不一样一部分应用不一样的网站地址开展收集,留意Url的设定。
XPath2Doc中文绿色版(通用网站数据采集及Doc生成工具)操作方法
起动程序流程--挑选模版--点一下采集数据按键周围的灰黑色三角符号,点开下拉列表,点一下必须收集的一部分。等待电脑浏览器载入网页页面结束,手工制作键入必须查寻的內容,点击查询,寻找数据信息的实际网页页面,随后点一下采集数据按键,观查右边的目录中是否早已获得必须的数据信息。再次点开下拉列表,挑选下一个必须收集的一部分,假如网站地址发生了转变要等待电脑浏览器载入结束,寻找必须的数据信息网页页面。点一下采集数据按键观查右边目录中是否获得了第二一部分的数据信息。这般不断,直至数据信息所有收集结束。
假如前后左右两一部分的网站地址同样,在点一下下一部分的下拉列表以前,要先在电脑浏览器中再次查寻新的数据信息,等新数据网页页面出去以后在点一下下拉列表挑选下一部分开展收集。(网站地址同样的状况下,点一下下一部分会立即从网页页面取数据信息,假如电脑浏览器沒有换网页页面,数据信息就不对。)假如某一一部分必须再次收集,请先点一下下拉列表中的该一部分名字,随后点一下收集按键反复收集该一部分(这时能够随便更改电脑浏览器的数据信息网页页面,获得的便是不一样企业数据信息)。
目录中收集获得的数据信息結果如果有误差,能够点击自主改动。XPath句子假如有哪些不正确,还可以自身改动看检测結果(XPath句子在改动后会马上再次爬取电脑浏览器的数据信息,因此电脑浏览器最好合理数据信息网页页面),在程序流程中改动的XPath句子,不容易储存到INI文档中,请自主手工制作储存。
假如目录中数据准确无误,浏览对话框中的Docx模版內容也恰当,则能够点一下建立文本文档按键,填好要转化成的文件夹名称,本pc软件会应用爬取到的网页页面数据信息更换模版中的数据库索引字符串数组,自动生成Docx文本文档。
必须表明的是,右下方的Docx浏览对话框不可以详细的适用Word文本文档,对不规范的文本文档很有可能会出現文字缺少或是移位状况。碰到这类状况,能够忽视,或是将模版文档改为标准的文档格式(单倍行距)。
- 2021-08-12 office2016 2019 365正版超低价购买方法
 Karaoke Anything英文安装版(卡拉OK歌曲歌词删除器)简体 / 2.37 MB
Karaoke Anything英文安装版(卡拉OK歌曲歌词删除器)简体 / 2.37 MB
 QQ音乐qmc3文件转mp3解码器绿色免费版简体 / 5.88 MB
QQ音乐qmc3文件转mp3解码器绿色免费版简体 / 5.88 MB
 好易MP4格式转换器官方安装版简体 / 5.72 MB
好易MP4格式转换器官方安装版简体 / 5.72 MB
 利用短网址进行文本的存储工具绿色版简体 / 447.33 KB
利用短网址进行文本的存储工具绿色版简体 / 447.33 KB
 世界之窗浏览器极速版简体 / 21.75 MB
世界之窗浏览器极速版简体 / 21.75 MB
 世界之窗浏览器官方安装版简体 / 19.64 MB
世界之窗浏览器官方安装版简体 / 19.64 MB
 Bypass分流抢票(12306分流抢票软件)V1.14.4 绿色版简体 / 4.28 MB
Bypass分流抢票(12306分流抢票软件)V1.14.4 绿色版简体 / 4.28 MB
 看看宝盒安卓版
影音播放
看看宝盒安卓版
影音播放
 地摊记账王
生活服务
地摊记账王
生活服务
 今川课堂
效率办公
今川课堂
效率办公
 句子转换器
资讯阅读
句子转换器
资讯阅读
 中国教师研修网
效率办公
中国教师研修网
效率办公
 Painter安卓版
效率办公
Painter安卓版
效率办公
 嘿嘿连载安卓版
资讯阅读
嘿嘿连载安卓版
资讯阅读
 格子酱
系统工具
格子酱
系统工具
 Video
摄影摄像
Video
摄影摄像