
PiFlow官方版(大数据流水线系统)
立即下载- 软件大小:301.98 MB
- 软件版本:最新版本
- 软件分类:行业软件
- 软件语言:简体中文
- 软件支持:Win All
- 发布时间:2021-09-23 02:58:44
- 软件评分:



- 软件介绍
- 相关下载
- 同类最新
- 软件攻略
- 评论留言
- 下载地址
PiFlow官方版(大数据流水线系统)是一款行业软件软件,officeba免费提供PiFlow官方版(大数据流水线系统)下载,更多PiFlow官方版(大数据流水线系统)相关版本就在officeba。
PiFlow是一款十分强劲的互联网大数据生产流水线系统软件,复合型科学研究互联网大数据生产流水线系统软件,这款系统软件将数据收集、存储的等阶段封装成部件,pc软件简易应用非常容易,给予100 的数据处理方法部件,如果有必须盆友的能够来本网站免费下载试一下。
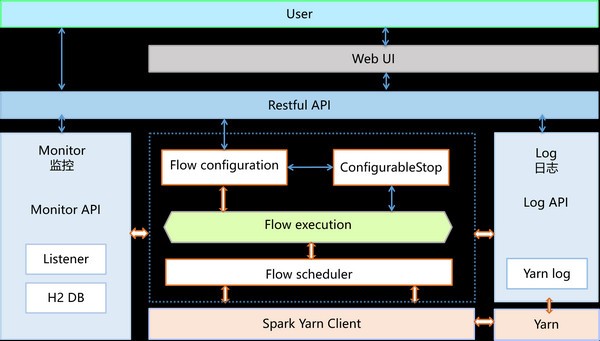
PiFlow官方版(大数据流水线系统)pc软件特点
简易实用。
数据可视化配备生产流水线。
监管生产流水线。
查询生产流水线日志。
控制点作用。
扩展性强:
适用自定开发设计数据处理方法部件。
使用性能:
根据分布式计算模块Spark开发设计。
功能齐全:
给予100 的数据处理方法部件。
包含Hadoop 、Spark、MLlib、Hive、Solr、Redis、MemCache、ElasticSearch、JDBC、MongoDB、HTTP、FTP、XML、CSV、JSON等。
集成化了微生物菌种行业的有关优化算法。
PiFlow官方版(大数据流水线系统)操作方法
缓解压力piflow-server-v0.9.tar.gz。
tar -zxvf piflow-server-v0.9.tar.gz。
编写环境变量config.properties。
运作、终止、重新启动PiFlow Server。
start.sh、stop.sh、 restart.sh、 status.sh。
检测 PiFlow Server。
设定系统变量 PIFLOW_HOME。
vim /etc/profile。
export PIFLOW_HOME=/yourPiflowPath/bin。
export PATH=PATH:PIFLOW_HOME/bin。
运作以下指令。
piflow flow start example/mockDataFlow.json。
piflow flow stop appID。
piflow flow info appID。
piflow flow log appID。
piflow flowGroup start example/mockDataGroup.json。
piflow flowGroup stop groupId。
piflow flowGroup info groupId。
如何配置config.properties。
#spark and yarn config。
spark.master=yarn。
spark.deploy.mode=cluster。
#hdfs default file system。
fs.defaultFS=hdfs://10.0.86.191:9000。
#yarn resourcemanager.hostname。
yarn.resourcemanager.hostname=10.0.86.191。
#if you want to use hive, set hive metastore uris。
#hive.metastore.uris=thrift://10.0.88.71:9083。
#show data in log, set 0 if you do not want to show data in logs。
data.show=10。
#server port
server.port=8002
#h2db port
h2.port=50002
- 2021-08-12 office2016 2019 365正版超低价购买方法
 Karaoke Anything英文安装版(卡拉OK歌曲歌词删除器)简体 / 2.37 MB
Karaoke Anything英文安装版(卡拉OK歌曲歌词删除器)简体 / 2.37 MB
 QQ音乐qmc3文件转mp3解码器绿色免费版简体 / 5.88 MB
QQ音乐qmc3文件转mp3解码器绿色免费版简体 / 5.88 MB
 好易MP4格式转换器官方安装版简体 / 5.72 MB
好易MP4格式转换器官方安装版简体 / 5.72 MB
 Praat32位官方版(语音学软件)简体 / 10.23 MB
Praat32位官方版(语音学软件)简体 / 10.23 MB
 塔尖用车单位版官方版简体 / 48.47 MB
塔尖用车单位版官方版简体 / 48.47 MB
 优房管家旗舰版官方版简体 / 20.53 MB
优房管家旗舰版官方版简体 / 20.53 MB
 银泰证券V6网上交易官方版简体 / 39.48 MB
银泰证券V6网上交易官方版简体 / 39.48 MB
 看看宝盒安卓版
影音播放
看看宝盒安卓版
影音播放
 地摊记账王
生活服务
地摊记账王
生活服务
 今川课堂
效率办公
今川课堂
效率办公
 句子转换器
资讯阅读
句子转换器
资讯阅读
 中国教师研修网
效率办公
中国教师研修网
效率办公
 Painter安卓版
效率办公
Painter安卓版
效率办公
 嘿嘿连载安卓版
资讯阅读
嘿嘿连载安卓版
资讯阅读
 格子酱
系统工具
格子酱
系统工具
 Video
摄影摄像
Video
摄影摄像